在前一章中我们已经感受到完全用React来管理应用数据的麻烦,在这一章中,我们将介绍Redux这种管理应用状态的框架
本章包含以下内容:
单向数据流框架的始祖Flux
Flux理念的一个更强实现Redux
结合React和Redux
一、Flux
要了解Redux,首先要从Flux说起,可以认为Redux是Flux思想的另一种实现方式,通过了解Flux,我们可以知道Flux一族框架(其中就包括Redux)贯彻的最重要的观点——单向数据流,更重要的是,我们可以发现Flux框架的缺点,从而深刻地认识到Redux相对于Flux的改进之处。
让我们来看看Flux的历史,实际上,Flux是和React同时面世的,在2013年,Facebook公司让React亮相的同时,也推出了Flux框架,React和Flux相辅相成,Facebook认为两者结合在一起才能构建大型的JavaScript应用。
做一个容易理解的对比,React是用来替换jQuery的,那么Flux就是以替换Backbone.js、Ember.js等MVC一族框架为目的。
在MVC(Model-View-Controller)的世界里,React相当于V(View)的部分,只涉及页面的渲染,一旦涉及应用的数据管理部分,还是交给Model和Controller,不过,Flux并不是一个MVC框架,事实上,Flux认为MVC框架存在很大问题,它推翻了MVC框架,并用一个新的思维来管理数据流转。
1. MVC框架的缺陷
MVC框架是业界广泛接受的一种前端应用框架类型,这种框架把应用分成三个部分:
Model(模型):负责管理数据,大部分业务逻辑也应该放在Model中
View(视图):负责渲染用户界面,应该避免在View中涉及业务逻辑
Controller(控制器):负责接受用户输入,根据用户输入调用对应的Model部分逻辑,把产生的数据结果交给View部分,让View渲染出必要的输出。
MVC框架的几个组成部分和请求的关系如图所示
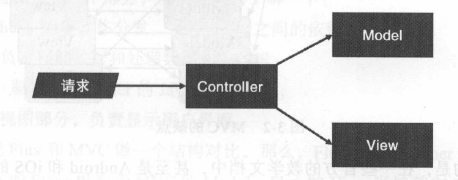
这样的逻辑划分,实质上与把以一个应用划分为多个组件一样,就是“分而治之”。毫无疑问,相比把业务逻辑和界面渲染逻辑混在一起,MVC框架要先进得多。这种方式得到了广泛的认可,连Facebook最初也是用这种框架。
但是,Facebook的工程部门逐渐发现,对于非常巨大的代码库和庞大的组织,按照他们的原话说就是“MVC真的很快就变得非常复杂”。每当工程师想要增加一个新的功能时,对代码的修改很容易引入新的bug,因为不同模块之间的依赖关系让系统变得“脆弱而且不可预测”。对于刚刚加入团队的新手,更是举步维艰,因为不知道修改代码会造成什么样的后果。如果要保险,就会发现寸步难移;如果放手去干,就可能引发很多bug。
一句话,MVC根本不适合Facebook的需求。
为何被业界普遍认可的MVC框架在Facebook眼里却沦落到如此地步呢?
下图是Facebook描述的MVC框架,在图中我们可以看到,Model和View之间缠绕着蜘蛛网一样复杂的依赖关系,根据箭头的方向,我们知道有的是Model调用了View,有的是View调用了Model,很乱。
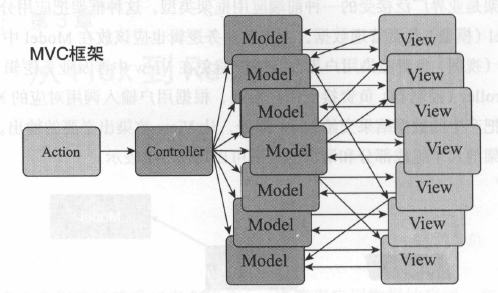
MVC框架提出的数据流很理想,用户请求先到达Controller,由Controller调用Model获得数据,然后把数据交给View,但是,在实际框架实现中,总是允许View和Model可以直接通信,从而出现上图的情况。越来越多的同行发现,在MVC中让View和Model直接对话就是灾难。
当我向以前没接触过Flux的朋友介绍Flux的时候,发现了一个有意思的现象。凡是只在服务器端使用过MVC框架的朋友,就很容易理解和接受Flux。而对于已经有很多浏览器端MVC框架经验的朋友,往往还要费一点劲才能明白MVC和Flux的差异。
造成这种认知差别的主要原因,就是服务器端MVC框架往往就是每个请求就只在Controller-Model-View三者之间走一圈,结果就返回给浏览器去渲染或者其他处理了,然后这个请求生命周期的Controller-Model-View就可以回收销毁了,这是一个严格意义的单向数据流;对于浏览器端MVC框架,存在用户的交互处理,界面渲染出来之后,Model和View依然处在于浏览器中,这时候就会诱惑开发者为了简便,让现存的Model和View直接对话。
对于MVC框架,为了让数据流可控,Controller应该是中心,当View要传递消息给Model时,应该调用Controller的方法,同样,当Model要更新View时,也应该通过Controller引发新的渲染。
当Facebook推出Flux时,招致了很多质疑。很多人都说,Flux只不过是一个对数据流管理更加严格的MVC框架而已。这种说法不完全准确,但是一定意义上也说明了Flux的一个特点:更严格的数据流控制。
Facebook无心在MVC框架上纠缠,他们用Flux框架来代替原有的MVC框架,他们提出的Flux框架大致结构如图所示
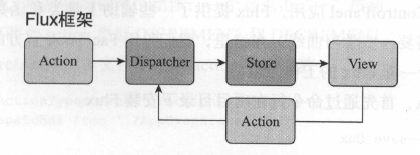
一个Flux应用包含四个部分,我们先粗略了解一下:
Dispatcher:处理动作分发,维持Store之间的依赖关系
Store:负责存储数据和处理数据相关逻辑
Action:驱动Dispatcher的JavaScript对象
View:视图部分,负责显示用户界面
如果非要把Flux和MVC做一个结构对比,那么,Flux的Dispatcher相当于MVC的Controller,Flux的Store相当于MVC的Model,Flux的View当然就对应MVC的View,至于多出来的这个Action,可以理解为对应MVC框架的用户请求。
在MVC框架中,系统能够提供什么样的服务,通过Controller暴露函数来实现。每增加一个功能,Controller往往就要增加一个函数;在Flux的世界里,新增加功能并不需要Dispatcher增加新的函数,实际上,Dispatcher自始至终只需要暴露一个函数Dispatch,当需要增加新的功能时,要做的是增加一种新的Action类型,Dispatcher的对外接口并不用改变。
当需要扩充应用所能处理的“请求”时,MVC方法就需要增加新的Controller,而对于Flux则只是增加新的Action。
下面我们看看怎么用Flux改进我们的React应用。
** 2. Flux应用
让我们改进一下前面创造的ControlPanel应用,Flux提供了一些辅助工具类和函数,能够帮助创建Flux应用,但是需要一些学习曲线。在这里,我们只用Facebook官方的基本功能,目的是为了更清晰地看一看Flux的工作原理。
首先通过命令行在项目目录下安装Flux。
1 | npm install --save flux |
利用Flux实现ControlPanel应用后的界面效果与前面创造的应用完全一样,通过同一界面不同实现方式的比对,我们可以体会每个方式的优劣。
- 1) Dispatcher
首先,我们要创造一个Dispatcher,几乎所有应用都只需要拥有一个Dispatcher,对于我们这个简单的应用更不例外。在src/AppDispatcher.js中,我们创造这个唯一的Dispatcher对象,代码如下:
1 | import {Dispatcher} from 'flux'; |
非常简单,我们引入flux库中的Dispatcher类,然后创造一个新的对象作为这个文件的默认输出就足够了。在其他代码中,将会引用这个全局唯一的Dispatcher对象。
Dispatcher存在的作用,就是用来派发action,接下来我们就来定义应用中涉及的action。
- 2) action
action顾名思义代表一个“动作”,不过这个动作只是一个普通的JavaScript对象,代表一个动作的纯数据,类似于DOM API中的事件(event)。甚至,和事件相比,action其实还是更加纯粹的数据对象,因为事件往往还包含一些方法,比如点击事件就有preventDefault方法,但是action对象不自带方法,就是纯粹的数据。
作为管理,action对象必须有一个名为type的字段,代表这个action对象的类型,为了记录日志和debug方便,这个type应该是字符串类型。
定义action通常需要两个文件,一个定义action的类型,一个定义action的构造函数(也称为action creator)。分成两个文件的主要原因是Store中会根据action类型做不同操作,也就有单独导入action类型的需要。
在src/ActionTypes.js中,我们定义action的类型,代码如下:
1 | export const INCREMENT = 'increment'; |
在这个例子中,用户只能做两个动作,一个是点击“+”按钮,一个是点击“-”按钮,所以我们只有两个action类型INCREMENT和DECREMENT。
现在我们在src/Actions.js文件中定义action构造函数:
1 | import * as ActionTypes from './ActionTypes.js'; |
虽然出于业界习惯,这个文件被命名为Actions.js,但是要注意里面定义的并不是action对象本身,而是能够产生并派发action对象的函数。
在Actions.js文件中,引入了ActionTypes和AppDispatcher,看得出来是要直接使用Dispatcher。
这个Actions.js导出了两个action构造函数increment和decrement,当这两个函数被调用的时候,创造了对应的action对象,并立即通过AppDispatcher.dispatch函数派发出去。
派发出去的action对象最后怎么样了呢?下面关于Store的部分可以看到。
- 3) Store
一个Store也是一个对象,这个对象存储应用状态,同时还要接受Dispatcher派发的动作,根据动作来决定是否要更新应用状态。
接下来我们创造Store相关的代码,因为使用Flux之后代码文件数量会增多,再把所有源代码文件都放在src目录下就不容易管理了。所以我们在src下创建一个子目录stores,在这个子目录里放置所有的Store代码。
在前面章节的ControlPanel应用例子里,有三个Counter组件,还有一个统计三个Counter计数值之和的功能,我们遇到的麻烦就是这两者之间的状态如何同步的问题,现在,我们创造两个Store,一个是为Counter组件服务的CounterStore,另一个就是为总数服务的SummaryStore。
我们首先添加CounterStore,放在src/stores/CounterStore.js文件中。
1 | const counterValues = { |
当Store的状态发生变化的时候,需要通知应用的其它部分做必要的响应。在我们的应用中,做出响应的部分当然就是View部分,但是我们不应该硬编码这种联系,应该用消息的方式建立Store和View的联系。这就是为什么我们让CounterStore扩展了EventEmitter.prototype,等于让CounterStore成了EventEmitter对象,一个EventEmitter实例对象支持下列相关函数。
emit函数,可以广播一个特定事件,第一个参数是字符串类型的事件名称
on函数,可以增加一个挂在这个EventEmitter对象特定事件上的处理函数,第一个参数是字符串类型的事件名称,第二个参数是处理函数
removeListener函数,和on函数做的事情相反,删除挂在这个EventEmitter对象特定事件上的处理函数,和on函数一样,第一个参数是事件名称,第二个参数是处理函数。要注意,如果要调用removeListener函数,就一定要保留对处理函数的引用
对于CounterStore对象,emitChange、addChangeListener和removeChangeListener函数就是利用EventEmitter上述的三个函数完成对CounterStore状态更新的广播、添加监听函数和删除监听函数等操作。
CounterStore函数还提供一个getCounterValues函数,用于让应用中其他模块可以读取当前的计数值,当前的计数值存储在文件模块级的变量counterValues中。
上面实现的Store只有注册到Dispatcher实例上才能真正发挥作用,所以还需要增加下列代码
1 | import AppDispatcher from '../AppDispatcher.js'; |
这是最重要的一个步骤,要把CounterStore注册到全局唯一的Dispatcher上去。Dispatcher有一个函数叫做register,接受一个回调函数作为参数。返回值是一个token,这个token可以用于Store之间的同步,我们在CounterStore中还用不上这个返回值,在稍后的SummaryStore中会用到,现在我们只是把register函数的返回值保存在CounterStore对象的dispatchToken字段上,待会就会用得到。
现在我们来仔细看看register接受的这个回调函数参数,这是Flux流程中最核心的部分,当通过register函数把一个回调函数注册到Dispatcher之后,所有派发给Dispatcher的action对象,都会传递到这个回调函数中来。
比如通过Dispatcher派发一个动作,代码如下:
1 | AppDispatcher.dispatch({ |
那在CounterStore注册的回调函数就会被调用,唯一的一个参数就是那个action对象,回调函数要做的,就是根据action对象来决定如何更新自己的状态。
作为一个普遍接受的传统,action对象中必须要有一个type字段,类型是字符串,用于表示这个action对象是什么类型,比如上面派发的action对象,type为“increment”,表示是一个计数器“加一”的动作;如果有必要,一个action对象还可以包含其他的字段。上面的action对象中还有一个counterCaption字段值为“First”,标识名字为“First”的计数器。
在我们的例子中,action对象的type和counterCaption字段结合在一起,可以确定是哪个计数器应该做加一或者减一的动作,上面例子中的动作含义就是:“名字为First的计数器要做加一动作。”
根据不同的type,会有不同的操作,所以注册的回调函数很自然有一个模式,就是函数体是一串if-else条件语句或者switch条件语句,而条件语句的跳转条件,都是针对参数action对象的type字段:
1 | CounterStore.dispatchToken = AppDispatcher.register((action) => { |
无论是加一还是减一,最后都要调用counterStore.emitChange函数,假如有调用者通过Counter.addChangeListener关注了CounterStore的状态变化,这个emitChange函数调用就会引发监听函数的执行。
目前,CounterStore只关注INCREMENT和DECREMENT动作,所以if-else判断也只关注了这两种类型的动作,除此之外,其他action对象一律忽略。
接下来,我们再来看看另一个Store,也就是代表所有计数器计数值综合的Store,在src/stores/SummaryStore.js中。
SummaryStore也有emitChange、addChangeListener还有removeChangeListener函数,功能一样也是用于通知监听者状态变化,这几个函数的代码和CounterStore中完全重复,不同点是对获取状态函数的定义,代码如下:
1 | function computeSummary(counterValues) { |
可以注意到,SummaryStore并没有存储自己的状态,当getSummary被调用时,它是直接从CounterStore里获取状态计算的。
CounterStore提供了getCounterValues函数让其他模块能够获得所有计数器的值,SummaryStore也提供了getSummary让其他模块可以获得所有计数器当前的总和。不过,既然总可以通过CounterStore.getCounterValues函数获取最新鲜的数据,SummaryStore似乎也就没有必要把计数器总和存储到某个变量里。事实上,可以看到SummaryStore并不像CounterStore一样用一个变量counterValues存储数据,SummaryStore不存储数据,而是每次对getSummary的调用,都实时读取CounterStore.getCounterValues,然后实时计算总和返回给调用者。
可见,虽然名为Store,但并不表示一个Store必须要存储什么东西,Store只是提供获取数据的方法,而Store提供的数据完全可以另一个Store计算得来。
SummaryStore在Dispatcher上注册的回调函数也和CounterStore很不一样,代码如下:
1 | SummaryStore.dispatchToken = AppDispatcher.register((action) => { |
SummaryStore同样也通过AppDispatcher.register函数注册了一个回调函数,用于接受派发的action对象。在回调函数中,也只关注了INCREMENT和DECREMENT类型的action对象,并通过emitChange通知监听者,注意在这里使用了waitFor函数,这个函数解决的是下面描述的问题。
既然一个action对象会被派发给所有回调函数,这就产生了一个问题,到底是按照什么顺序调用各个回调函数呢?
即使Flux按照register调用的顺序去调用各个回调函数,我们也完全无法把握各个Store哪个先装载从而调用register函数。所以,可以认为Dispatcher调用回调函数的顺序完全是无法预期的,不要假设它会按照我们期望的顺序逐个调用。
怎么解决这个问题呢?这就要靠Dispatcher的waitFor函数了。在SummaryStore的回调函数中,之前在CounterStore中注册回调函数时保存下来的dispatchToken终于派上用场了。
Dispatcher的waitFor可以接受一个数组作为参数,数组中的每个元素都是一个Dispatcher.register函数的返回结果,也就是所谓的dispatchToken。这个waitFor函数告诉Dispatcher,当前的处理必须要暂停,直到dispatchToken代表的那些已注册回调函数执行结束才能继续。
我们知道,JavaScript是单线程语言,不可能有线程之间的等待这回事,这个waitFor函数当然不是用多线程实现的,只是在调用waitFor的时候,把控制权交给Dispatcher,让Dispatcher检查一下dispatchToken代表的回调函数有没有被执行,如果已经执行,那就直接继续,如果还没有执行,那就调用dispatchToken代表的回调函数之后waitFor才返回。
回到我们上面的例子,即使SummaryStore比CounterStore提前接收到了action对象,在emitChange中调用waitFor,也就能够保证emitChange函数被调用的时候,CounterStore也已经处理过这个action对象。
这里要注意一个事实,Dispatcher的register函数,只提供了一个回调函数的功能,但却不能让调用者在register时选择只监听某些action,换句话说,每个register的调用者只能这样请求:“当有任何动作被派发时,请调用我。”但不能够这么请求:“当这种类型还有那种类型的动作被派发的时候,请调用我。”
当一个动作被派发的时候,Dispatcher就是简单地把所有注册的回调函数全都调用一遍,至于这个动作是不是对方关心的,Flux的Dispatcher不关心,要求每个回调函数去鉴别。
看起来,这似乎是一种浪费,但是这个设计让Flux的Dispatcher逻辑最简单化,Dispatcher的责任越简单,就越不会出现问题。毕竟,由回调函数全权决定如何处理action对象,也是非常合理的。
- 4) View
首先要说明,Flux框架下,View并不是说必须要使用React,View本身是一个独立的部分,可以用任何一种UI库来实现。
不过,话说回来,既然我们都使用上Flux了,除非项目有大量历史遗留代码,否则实在没有理由不用React来实现View。
存在于Flux框架中的React组件需要实现以下几个功能:
创建时要读取Store上状态来初始化组件内部状态
当Store上状态发生变化时,组件要立刻同步更新内部状态保持一致
View如果要改变Store状态,必须且只能派发action
最后让我们来看看例子中的View部分,为了方便管理,所有View文件都放在src/views目录里。
先看src/views/ControlPanel.js中的ControlPanel组件,其中render函数的实现和上一章很不一样,代码如下:
1 | render() { |
可以注意到,和前面章节中的ControlPanel不同,Counter组件实例只有caption属性,没有initValue属性。因为我们把计数值包括初始值全都放到CounterStore中去了,所以在创造Counter组件实例的时候就没必要指定initValue了。
接着看src/views/Counter.js中定义的Counter组件,构造函数中初始化this.state的方式有了变化,代码如下:
1 | constructor(props) { |
在构造函数中,CounterStore.getCounterValues函数获得了所有计数器的当前值,然后把this.state初始化为对应caption字段的值,也就是说Counter组件的store来源不再是prop,而是Flux的Store。
Counter组件中的state应该成为Flux Store上状态的一个同步镜像,为了保持两者一致,除了在构造函数中的初始化之外,在之后当CounterStore上状态变化时,Counter组件也要对应变化,代码如下:
1 | componentDidMount() { |
如上面的代码所示,在componentDidMount函数中通过CounterStore.addChangeListener函数监听了CounterStore的变化之后,只要CounterStore发生变化,Counter组件的onChange函数就会被调用。与componentDidMount函数中监听事件对应,在componentWillUnmount函数中删除了这个监听。
接下来,要看React组件如何派发action,代码如下:
1 | onClickIncrementButton() { |
可以注意到,在Counter组件中有两处用到CounterStore的getCounterValues函数的地方,第一处在构造函数中初始化this.state的时候,第二处是在响应CounterStore状态变化的onChange函数中,同样一个Store的状态,为了转换为React组件的状态,有两次重复的调用,这看起来似乎不是很好。但是,React组件的状态就是这样,在构造函数中要对this.state初始化,要更新它就要调用this.setState函数。
有没有更简洁的办法?比如说只使用CounterStore.getCounterValues一次?可惜,只要我们想用组件的状态来驱动组件的渲染,就不可避免要有这两步。那么如果我们不利用组件的状态呢?
如果不使用组件的状态,那么我们就可以逃出这个必须在代码中使用Store两次的宿命,在接下来的章节里,我们会遇到这种“无状态”组件。
Summary组件,存在于src/views/Summary.js中,和Counter类似,在constructor中初始化组件状态,通过在componentDidMount中添加对SummaryStore的监听来同步状态,因为这个View不会有任何交互功能,所以没有派发出任何action。
3. Flux的优势
本章的例子和上一章我们只用React的实现效果一样,但是工作方式有了大变化。
回顾一下完全只用React实现的版本,应用的状态数据只存在于React组件之中,每个组件都要维护驱动自己渲染的状态数据,单个组件的状态还好维护,但是如果多个组件之间的状态有关联,但就麻烦了。比如Counter组件和Summary组件,Summary组件就需要维护所有Counter组件计数值的总和,Counter组件和Summary组件分别维护自己的状态,如何同步Summary和Counter状态就成了问题,React只提供了props方法让组件之间通信,组件之间关系稍微复杂一点,这种方式就显得非常笨拙。
Flux架构下,应用的状态被放在了Store中,React组件只是扮演View的作用,被动根据Store的状态来渲染。在上面的例子中,React组件依然有自己的状态,但是已经完全沦为Store组件的一个映射,而不是主动变化的数据。
在完全只用React实现的版本里,用户的交互操作,比如点击“+”按钮,引发的事件处理函数直接通过this.setState改变组件的状态。在Flux的实现版本里,用户的操作引发的是一个“动作”的派发,这个派发的动作会发送给所有的Store对象,引起Store对象的状态改变,而不是直接引发组件的状态改变。因为组件的状态是Store状态的映射,所以改变了Store对象也就触发了React组件对象的状态改变,从而引发了界面的重新渲染。
Flux带来了哪些好处呢?最重要的就是“单向数据流”的管理方式。
在Flux的理念里,如果要改变界面,必须改变Store中的状态,如果要改变Store中的状态,就必须派发一个action对象,这就是规矩。在这个规矩之下,想要追溯一个应用的逻辑就变得非常容易。
我们已经讨论过MVC框架的缺点,MVC最大的问题就是无法禁绝View与Model之间的直接对话,对应于MVC中的View就是Flux中的View,对应于MVC中Model的就是Flux中的Store。在Flux中,Store只有get方法,没有set方法,根本不可能直接去修改其内部状态,View只能通过get方法获取Store的状态,无法直接去修改状态,如果View想要修改Store状态的话,只有派发一个action给Dispatcher。
这看起来是一个“限制”,但却是一个很好地“限制”,禁绝了数据流混乱的可能。
简单来说,Flux的体系下,驱动界面改变始于一个动作的派发,别无他法。
4. Flux的不足
任何工具不可能只有优点没有缺点,接下来让我们看看Flux的不足之处,只有了解了Flux的不足之处,才能理解为什么会出现Flux的改进框架Redux。
- 1) Store之间的依赖关系
在Flux的体系中,如果两个Store之间有逻辑依赖关系,就必须用上Dispatcher的waitFor函数。在上面的例子中我们已经使用过waitFor函数,SummaryStore对action的处理,依赖于CounterStore已经处理过了。所以,必须要通过waitFor函数告诉Dispatcher,先让CounterStore处理这些action对象,只有CounterStore搞定之后SummaryStore才继续。
那么,SummaryStore如何标识CounterStore呢?靠的是register函数的返回值dispatchToken,而dispatchToken的产生,当然是CounterStore控制的,换句话说,要这样设计:
CounterStore必须要把注册回调函数时产生的dispatchToken公之于众
SummaryStore必须要在代码里建立对CounterStore的dispatchToken的依赖
虽然Flux这个设计的确解决了Store之间的依赖关系,但是,这样明显的模块之间的一来,看着还是让人感觉不太舒服,毕竟最好的依赖管理是根本不让依赖产生。
- 2) 难以进行服务器端渲染
关于服务器端渲染,我们在后面会详细介绍,在这里,我们只需要知道,如果要在服务器端渲染,输出不是一个DOM树,而是一个字符串,准确来说就是一个全是HTML的字符串。
在Flux的体系中,有一个全局的Dispatcher,然后每一个Store都是一个全局唯一的对象,这对于浏览器端应用完全没有问题,但是如果放在服务器端,就会有大问题。
和一个浏览器网页只服务于一个用户不同,在服务器端要同时接受很多用户的请求,如果每个Store都是全局唯一对象,那不同请求的状态肯定就乱套了。
并不是说Flux不能做服务器端渲染,只是说让Flux做服务器端渲染很困难,实际上,Facebook也说得很清楚,Flux不是设计用作服务器端渲染的,他们也从来没有尝试过把Flux应用于服务器端。
- 3) Store混杂了逻辑和状态
Store封装了数据和处理数据的逻辑,用面向对象的思维来看,这是一件好事,毕竟对象就是这样定义的。但是,当我们需要动态替换一个Store的逻辑时,只能把这个Store整体替换掉,那也就无法保持Store中存储的状态。
在开发模式下,开发人员要不停地对代码进行修改,如果Store在某个状态下引发了bug,如果能在不毁掉状态的情况下替换Store的逻辑,那就最好了,开发人员就可以不断地改进逻辑来验证这个状态下bug是否被修复了。
还有一些应用,在生产环节下就要根据用户属性来动态加载不同的模块,而且动态加载模块还希望不要网页重新加载,这时候也希望能够在不修改应用状态的前提下重新加载应用逻辑,这就是热加载,后面章节会介绍如何实现热加载。
二、Redux
我们把Flux看作一个框架理念的话,Redux是Flux的一种实现,除了Redux之外,还有很多实现Flux的框架,比如Reflux、Fluxible等,毫无疑问Redux获得的关注最多,这不是偶然的,因为Redux有很多其他框架无法比拟的优势。
1. Redux的基本原则
2013年问世的Flux饱受争议,而2015年Dan Abramov提出了在Flux基础上的改进框架Redux,则是一鸣惊人,在所有Flux的变体中算是最受关注的框架,没有之一。
Flux的基本原则是“单向数据流”,Redux在此基础上强调三个原则:
唯一数据源(Single Source of Truth)
保持状态只读(State is read-only)
数据改变只能通过纯函数完成(Changes are made with pure functions)
让我们逐一解释这三条基本原则
- 1) 唯一数据源
唯一数据源指的是应用的状态数据应该只存储在唯一的一个Store上。
我们已经知道,在Flux中,应用可以拥有多个Store,往往根据功能把应用的状态数据划分给若干个Store分别存储管理。比如,在上面的ControlPanel中,我们创造了CounterStore和SummaryStore。
如果状态数据分散在多个Store中,容易造成数据冗余,这样数据一致性方面就会出问题。虽然利用Dispatcher的waitFor方法可以保证多个Store之间的更新顺序,但是这又产生了不同Store之间的显示依赖关系,这种依赖关系的存在增加了应用的复杂度,容易带来新的问题。
Redux对这个问题的解决方法就是,整个应用只保持一个Store,所有组件的数据源就是这个Store上的状态。
这个唯一Store上的状态,是一个树形的结构,每个组件往往只是用树形对象上一部分的数据,而如何设计Store上状态的结构,就是Redux应用的核心问题,我们接下来会描述细节。
- 2) 保持状态只读
保持状态只读,就是说不能去直接修改状态,要修改Store的状态,必须要通过派发一个action对象完成,这一点,和Flux的要求并没有什么区别。
如果只看这个原则的字面意思,可能会让我们有些费解,还记得那个公式吗?UI=render(state),我们已经能够说过驱动用户界面更改的是状态,如果状态都是只读的不能修改,怎么可能引起用户界面的变化呢?
当然,要驱动用户界面渲染,就要改变应用的状态,但是改变状态的方法不是去修改状态的值,而是创建一个新的状态对象返回给Redux,由Redux完成新的状态的组装。
这就引出了下面的第三条原则。
- 3) 数据改变只能通过纯函数完成
这里所说的纯函数就是Reducer,Redux这个名字的前三个字母Red代表的就是Reducer。按照创作者Dan Abramov的说法,Redux名字的含义是Reducer+Flux。
Reducer不是一个Redux特定的术语,而是一个计算机科学中的通用概念,很多语言和框架都有对Reducer函数的支持。以JavaScript为例,数组类型就有reduce函数,接受的参数就是一个reducer,reduce做的事情就是把数组所有元素依次做“规约”,对每个元素都调用一次reducer,通过reducer函数完成规约所有元素的功能。
1 | [1, 2, 3, 4].reduce(function reducer(accumulation, item) { |
上面的代码中,reducer函数接受两个参数,第一个参数是上一次规约的结果,第二个参数是这一次规约的元素,函数体是返回两者之和,所以这个规约的结果就是所有元素之和。
在Redux中,每个reducer的函数签名如下所示:
1 | reducer(state, action) |
第一个参数state是当前的状态,第二个参数是接收到的action对象,而reducer函数要做的事情,就是根据state和action的值产生一个新的对象返回,注意reducer必须是纯函数,也就是说函数的返回结果必须完全由参数state和action决定,而且不产生任何副作用,也不能修改参数state和action对象。
让我们回顾一下Flux中的Store是如何处理函数的,代码如下:
1 | CounterStore.dispatchToken = AppDispatcher.register((action) => { |
Flux更新状态的函数只有一个参数action,因为状态是由Store直接管理的,所以处理函数中会看到代码直接更新state;在Redux中,一个实现同样功能的reducer代码如下:
1 | function reducer(state, action) => { |
可以看到reducer函数不光接受action为参数,还接受state为参数。也就是说,Redux的reducer只负责计算状态,却并不负责存储状态。
我们在后面的实例中会详细解释这个reducer的构造。
读到这里,读者可能会有一个疑问,从Redux的基本原则来看,Redux并没有赋予我们强大的功能,反而是给开发者增加了很多限制,开发者丧失了想怎么写就怎么写的灵活度。
“如果你愿意限制做事方式的灵活度,你几乎总会发现可以做得更好。” —— John Carmark
作为制作出《Doom》《Quake》这样游戏的杰出开发者,John Carmark这句话道出了软件开发中的一个真谛。
在计算机编程的世界里,完成任何一件任务,可能都有一百种以上的方法,但是无节制的灵活度反而让软件难以维护,增加限制是提高软件质量的法门。
2. Redux实例
前面我们用Flux实现了一个ControlPanel的应用,接下来让我们用Redux来重新实现一遍同样的功能,通过对比就能看出二者的差异。
React和Redux事实上是两个独立的产品,一个应用可以使用React而不是用Redux,也可以使用Redux而不是用React,但是,如果两者结合使用,没有理由不使用一个名叫react-redux的库,这个库能够大大简化代码的书写。
不过,如果一开始就使用react-redux,可能对其设计思路完全一头雾水,所以,我们的实例先不采用react-redux库,从最简单的Redux使用方法开始,初步改进,循序渐进地过渡到使用react-redux。
最基本的Redux实现,存在与本书对应Github的chapter-03/redux_basic目录中,在这里我们只关注使用Redux实现和使用Flux不同的地方。
首先看关于action对象的定义,和Flux一样,Redux应用习惯上把action类型和action构造函数分成两个文件定义,其中定义action类型的src/ActionTypes.js和Flux版本没有任何差别,但是src/Actions.js文件就不大一样了,代码如下:
1 | import * as ActionTypes from './ActionTypes.js'; |
和Flux的src/Actions.js文件对比就会发现,Redux中每个action构造函数都返回一个action对象,而Flux版本中action构造函数并不返回什么,而是把构造的动作函数立刻通过调用Dispatcher的dispatch函数派发出去。
这是一个习惯上的差别,接下来我们会发现,在Redux中,很多函数都是这样不做什么产生副作用的动作,而是返回一个对象,把如何处理这个对象的工作交给调用者。
在Flux中我们要用到一个Dispatcher对象,但是在Redux中,就没有Dispatcher这个对象了,Dispatcher存在的作用就是把一个action对象分发给了多个注册了的Store,既然Redux让全局只有一个Store,那么再创造一个Dispatcher也的确意义不大。所以,Redux中“分发”这个功能,从一个Dispatcher对象简化为Store对象上的一个函数dispatch,毕竟只有一个Store,要分发也是分发给这个Store,就调用Store上一个表示分发的函数,合情合理。
我们创造一个src/Store.js文件,这个文件输出全局唯一的那个Store,代码如下:
1 | import {createStore} from 'redux'; |
在这里,我们接触到了Redux库提供的createStore函数,这个函数第一个参数代表更新状态的reducer,第二个参数是状态的初始值,第三个参数可选,代表Store Enhancer,在这个例子中用不上,后面章节会详细介绍。
确定Store状态,是设计好Redux应用的关键。从Store状态的初始值看得出来,我们的状态是这样一个格式:状态上每个字段名代表Counter组件的名(caption),字段的值就是这个组件当前的计数值,根据这些状态字段,足够支撑三个Counter组件。
那么,为什么没有状态来支持Summary组件呢?因为Summary组件的状态,完全可以通过把Counter状态数值加在一起得到,没有必要制造冗余数据存储,这也符合Redux“唯一数据源”的基本原则。记住:Redux的Store状态设计的一个主要原则:避免冗余数据。
接下来看src/Reducer.js中定义的reducer函数,代码如下:
1 | import * as ActionTypes from './ActionTypes.js'; |
和Flux应用中每个Store注册的回调函数一样,reducer函数中往往包含以action.type为判断条件的if-else或者switch语句。
和Flux不同的是,多了一个参数state。在Flux的回调函数中,没有这个参数,因为state是由Store管理的,而不是由Flux管理的。Redux中把存储state的工作抽取出来交给Redux框架本身,让reducer只用关心如何更新state,而不要管state怎么存。
代码中使用了三个句号组成的扩展操作符,表示把state中所有字段扩展开,而后面对counterCaption值对应的字段会赋上新值,像下面的代码
1 | return {...state, [counterCaption]: state[counterCaption] + 1}; |
逻辑上等同于
1 | const newState = Object.assign({}, state); |
和Flux很不一样的是,在reducer中,绝对不能去修改参数中的state,如果我们直接修改state并返回false,代码如下,注意这不是正确写法:
1 | export default (state, action) => { |
像上面这样写,似乎更简单直接,但实际上犯了大错,因为reducer应该是一个纯函数,纯函数不应该产生任何副作用。
接下来,我们看View部分,View部分代码都在src/views目录下。看看src/views/ControlPanel.js,作为这个应用最顶层的组件ControlPanel,内容和Flux例子中没有任何区别。然后是Counter组件,存在于src/views/Counter.js中,这就和Flux不大一样了,首先是构造函数中初始化this.state的来源不同,代码如下:
1 | import store from '../Store.js'; |
和Flux例子一样,在这个视图文件中我们要引入Store,只不过这次我们引入的Store不叫CounterStore,而是一个唯一的Redux Store,所以名字就叫store,通过store.getState()能够获得store上存储的所有状态,不过每个组件往往只需要使用返回状态的一部分数据。为了避免重复代码,我们把从store获得状态的逻辑放在getOwnState函数中,这样任何关联Store状态的地方都可以重用这个函数。
和Flux实现的例子一样,仅仅在构造函数时根据store来初始化this.state还不够,要保持store上状态和this.state的同步,代码如下:
1 | onChange() { |
在componentDidMount函数中,我们通过Store的subscribe监听其变化,只要Store状态发生变化,就会调用这个组件的onChange方法;在componentWillUnmount函数中,我们把这个监听注销掉,这个清理动作和componentDidMount中的动作对应。
其实,这个增加监听函数的语句也可以写在构造函数里,但是为了让mount和unmount的对应看起来更清晰,在所有的例子中我们都把加载监听的函数放在componentDidMount中。
除了从store同步状态,视图中可能会想要改变store中的状态,和Flux一样,改变store中状态唯一的方法就是派发action,代码如下:
1 | onIncrement() { |
上面定义了onIncrement和onDecrement方法,在render函数中的JSX中需要使用这两种函数,代码如下:
1 | render() { |
在render函数中,对于点击“+”按钮和“-”按钮的onClick事件,被分别挂上了onIncrement函数和onDecrement函数,所做的事情就是派发对应的action对象出去。注意和Flux例子的区别,在Redux中,action构造函数只负责创建对象,要派发action就需要调用store.dispatch函数。
组件的render函数所显示的动态内容,要么来自于props,要么来自于自身状态。
然后再来看看src/views/Summary.js中的Summary组件,其中getOwnState函数的实现代码如下:
1 | getOwnState() { |
Summary组件的套路和Counter组件差不多,唯一值得一提的就是getOwnState函数的实现。因为Store的状态中只记录了各个Counter组件的计数值,所以需要在getOwnState状态中自己计算出所有计数值总和出来。
3. 容器组件和傻瓜组件
分析一下上面的Redux例子中的Counter组件和Summary组件部分,可以发现一个规律,在Redux框架下,一个React组件基本上就是要完成以下两个功能:
和Redux Store打交道,读取Store的状态,用于初始化组件的状态,同时还要监听Store的状态改变;当Store状态发生变化时,需要更新组件状态,从而驱动组件重新渲染;当需要更新Store状态时,就要派发action对象
根据当前props和state,渲染出用户界面
还记得那句话吗?让一个组件只专注做一件事,如果发现一个组件做的事情太多了,就可以把这个组件拆分成多个组件,让每个组件依然只专注于一件事。
如果React组件都是要包办上面说的两个任务,似乎做的事情也的确稍微多了一点。我们可以考虑拆分,拆分为两个组件,分别承担一个任务,然后把两个组件嵌套起来,完成原本一个组件完成的所有任务。
这样的关系里,两个组件是父子组件的关系。业界对于这样的拆分有多种叫法,承担第一个任务的组件,也就是负责和Redux Store打交道的组件,处于外层,所以被称为容器组件(Container Component);对于承担第二个任务的组件,也就是只专心负责渲染界面的组件,处于内层,叫做展示组件(Presentational Component)。
外层的容器组件又叫聪明组件(Smart Component),内层的展示组件又叫傻瓜组件(Dumb Component),所谓“聪明”还是“傻瓜”只是相对而言,并没有褒贬的含义。

傻瓜组件就是一个纯函数,根据props产生结果。说是“傻瓜”,这种纯函数实现反而体现了计算机编程中的大智慧,大智若愚。
而容器组件,只是做的事情涉及一些状态转换,虽然名字里有“聪明”,其实做的事情都有套路,我们很容易就能抽取出共同之处,复用代码完成任务,并不需要开发者极其聪明才能掌握。
在我们把一个组件拆分为容器组件和傻瓜组件的时候,不只是功能分离,还有一个比较大的变化,那就是傻瓜组件不再需要有状态了。
实际上,让傻瓜组件无状态,是我们拆分的主要目的之一,傻瓜组件只需要根据props来渲染结果,不需要state。
那么,状态哪里去了呢?全都交给容器组件去打点,这是它的责任。容器组件如何把状态传递给傻瓜组件呢?通过props。
值得一提的是,拆分容器组件和傻瓜组件,是设计React组件的一种模式,和Redux没有直接关系。在Flux或者任何一种其他框架下都可以使用这种模式,只不过为了引出后面的react-redux,我们才在这里开始介绍罢了。
我们还是通过例子来感受一下容器组件和傻瓜组件如何协同工作,对应的代码在chapter-03/redux_smart_dumb目录下,是前面chapter-03/redux_basic的改进,只有视图部分代码有改变。
在视图代码src/views/Counter.js中定义了两个组件,一个是Counter,这是傻瓜组件,另一个是CounterContainer,这是容器组件。
傻瓜组件Counter代码的逻辑前所未有的简单,只有一个render函数,代码如下:
1 | class Counter extends Component { |
可以看到,Counter组件完全没有state,只有一个render方法,所有的数据都来自于props,这种组件叫做“无状态”组件。
而CounterContainer组件承担了所有的和Store关联的工作,它的render函数所做的就是渲染傻瓜组件Counter而已,只负责传递必要的prop,代码如下:
1 | class CounterContainer extends Component { |
可以看到,这个文件export导出的不再是Counter组件,而是CounterContainer组件,也就是对于使用这个视图的模块来说,根本不会感受到傻瓜组件的存在,从外部看到的就只是容器组件。
对于无状态组件,其实我们可以进一步缩减代码,React支持只用一个函数代表的无状态组件,所以,Counter组件可以进一步简化,代码如下:
1 | function Counter(props) { |
因为没有状态,不需要用对象表示,所以连类都不要了,对于一个只有render方法的组件,缩略为一个函数足矣。
注意,改为这种写法,获取props就不能用this.props,而是通过函数的参数props获得,无状态组件的props参数和有状态组件的this.props内容和结构完全一样。
还有一种惯常写法,就是把解构赋值直接放在参数部分
1 | function Counter({caption, onIncrement, onDecrement, value}) { |
看src/views/Summary.js中,内容也被分解为了傻瓜组件Summary和SummaryContainer,方式和Counter差不多,不再赘述。
重新审阅代码,我们可以看到CounterContainer和SummaryContainer代码有很多相同之处,写两份实在是重复,既然都是套路,完全可以抽取出来,后面的章节会讲如何应用react-redux来减少重复代码。
4. 组件Context
在介绍react-redux之前,我们重新看一看现在的Counter和Summary组件文件,发现它们都直接导入Redux Store。
1 | import store from './Store.js'; |
虽然Redux应用全局就一个Store,这样的直接导入依然有问题。
在实际工作中,一个应用的规模会很大,不会所有的组件都放在一个代码库里,有时候还要通过npm方式引入第三方的组件。想想看,当开发一个独立的组件的时候,都不知道自己这个组件会存在于哪个应用中,当然不可能预先知道定义唯一Redux Store的文件位置了,所以,在组件中直接导入Store是非常不利于组件复用的。
一个应用中,最好只有一个地方需要直接导入Store,这个位置当然应该是在调用最顶层React组件的位置。在我们的ControlPanel例子中,就是应用的入口文件src/index.js中,其余组件应该避免直接导入Store。
不让组件直接导入Store,那就只能让组件的上层组件把Store传递下来了。首先想到的当然是用props,毕竟,React组件就是用props来传递父子组件之间的数据的。不过,这种方法有一个很大的缺陷,就是从上到下,所有的组件都要帮助传递这个props。
设想在一个嵌套多层的组件结构中,只有最里层的组件才需要使用Store,但是为了把Store从外层传递到最里层,就要求中间所有的组件都需要增加对这个store prop的支持,即使根本不使用它,这无疑很麻烦。
还是来看ControlPanel这个例子,最顶层的组件ControlPanel根本就不使用Store,如果仅仅为了让它传递一个prop给子组件Counter和Summary就要求它支持state prop,显然非常不合理。所以,用prop传递store不是一个好方法。
React提供了一个叫Context的功能,能够完美地解决这个问题。
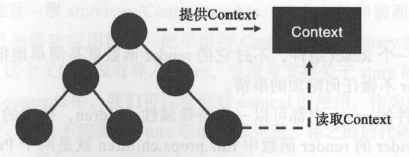
所谓Context,就是“上下文环境”,让一个树状组件上所有组件都能访问一个共同的对象,为了完成这个任务,需要上级组件和下级组件配合。
首先,上级组件要宣称自己支持context,并且提供一个函数来返回代表Context的对象。
然后,这个上级组件之下的所有下级组件,只要宣称自己需要这个Context,就可以通过this.context访问到这个共同的环境对象。
我们尝试给ControlPanel程序加上context功能来优化,相关代码在chapter-3/redux_with_context目录中,这个应用是对前面redux_smart_dumb的改进。
因为Redux应用中只有一个Store,因此所有组件如果要使用Store的话,只能访问这唯一的Store。很自然,希望顶层的组件来扮演这个Context提供者的角色,只要顶层组件提供包含store的context,那就覆盖了整个应用的所有组件,简单而且够用。
不过,每个应用的顶层组件不同,在我们的ControlPanel例子里顶层组件是ControlPanel,在另一个应用里会有另一个组件。而且,ControlPanel有它自己的职责,我们没有理由把它复杂化,没必要非要让它扮演context提供者的功能。
我们来创建一个特殊的React组件,它将是一个通用的context提供者,可以应用在任何一个应用中,我们把这个组件叫做Provider。在src/Provider.js中,首先定义一个名为Provider的React组件,代码如下:
1 | import {PropTypes, Component} from 'react'; |
Provider也是一个React组件,不过它的render函数就是简单地把子组件渲染出来,在渲染上,Provider不做任何附加的事情。
每个React组件的props中都可以包含一个特殊属性children,代表的是子组件,比如这样的代码,在Provider的render函数中this.props.children就是两个Provider标签之间的<ControlPanel />
1 | <Provider> |
除了把渲染工作完全交给子组件,Provider还要提供一个函数getChildContext,这个函数返回的就是代表Context的对象。我们的Context中只有一个字段store,而且我们也希望Provider足够通用,所以并不在这个文件中导入store,而是要求Provider的使用者通过prop传递进来store。
为了让Provider能够被React认可为一个Context的提供者,还需要指定Provider的childContextTypes属性,代码如下:
1 | Provider.childContextTypes = { |
Provider还需要定义类的childContextTypes,必须和getChildContext对应,只有这两者都齐备,Provider的子组件才有可能访问到context。
有了Provider,我们就可以改进一下应用的入口src/index.js文件了,代码如下:
1 | import store from './Store.js'; |
在前面所有的例子中,React.render的第一个参数就是顶层组件ControlPanel。现在,这个ControlPanel作为子组件被Provider包住了,Provider成为了顶层组件。当然,如同我们上面看到的,Provider只是把渲染工作完全交给子组件,它扮演的角色只是提供Context,包住了最顶层的ControlPanel,也就让context覆盖了整个应用中的所有组件。
至此,我们完成了提供Context的工作,接下来我们看底层组件如何使用Context。
我们可以顺便看一眼src/views/ControlPanel.js,这个文件和前面的例子没有任何变化,它做的工作只是搭建应用框架,把子组件Counter和Summary渲染出来,和Store一点关系都没有,这个文件既没有导入Store,也没有支持关于store的props。
在src/views/Counter.js中,我们可以看到对context的使用。作为傻瓜组件的Counter是一个无状态组件,它也不需要和Store牵扯什么关系,和之前的代码一模一样,有变化的是CounterContainer部分。
为了让CounterContainer能够访问context,必须给CounterContainer类的contextTypes赋值和Provider.childContextTypes一样的值,两者必须一致,不然就无法访问到context,代码如下:
1 | CounterContainer.contextTypes = { |
在CounterContainer中,所有对store的访问,都是通过this.context.store完成的,因为this.context就是Provider提供的context对象,所以getOwnState函数代码如下:
1 | getOwnState() { |
还有一点,因为我们自己定义了构造函数,所以要用上第二个参数context,代码如下:
1 | constructor(props, context) { |
在调用super的时候,一定要带上context参数,这样才能让React组件初始化实例中的context,不然组件的其它部分就无法使用this.context。
要求constructor显式声明props和context两个参数然后又传递给super看起来很麻烦,我们的代码似乎只是一个参数的搬运工,而且将来可能有新的参数出现那样又要修改这部分代码,我们可以用下面的方法一劳永逸地解决这个问题。
1 | constructor() { |
我们不能直接使用arguments,因为在JavaScript中arguments表现得像是一个数组而不是分开的一个个参数,但是我们通过扩展标识符就能把arguments彻底变成传递给super的参数。
在结束之前,让我们重新审视一下Context这个功能,Context这个功能相当于提供了一个全局可以访问的对象,但是全局对象或者说全局变量肯定是我们应该避免的用法,只要有一个地方改变了全局对象的值,应用中其它部分就会受影响,那样整个程序的运行结果就完全不可预测了。
所以,单纯来看React的这个Context功能的话,必须强调这个功能要谨慎使用,只有对那些每个组件都可能使用,但是中间组件又可能不使用的对象才有必要使用Context,千万不要滥用。
对于Redux,因为Redux的Store封装得很好,没有提供直接修改状态的功能,就是说一个组件虽然能够访问全局唯一的Store,却不可能直接修改Store中的状态,这样部分克服了作为全局对象的缺点。而且,一个应用只有一个Store,这个Store是Context里唯一需要的东西,并不算滥用,所以,使用Context来传递Store是一个不错的选择。
5. React-Redux
在上面两节中,我们了解了改进React应用的两个方法,第一是把一个组件拆分为容器组件和傻瓜组件,第二是使用React的Context来提供一个所有组件都可以直接访问的Context,也不难发现,这两种方法都有套路,完全可以把套路部分抽取出来复用,这样每个组件的开发只需要关注于不同的部分就可以了。
实际上,已经有这样的一个库来完成这些工作了,这个库就是react-redux。
在本书的chapter-03/react-redux目录下,可以看到利用react-redux实现的ControlPanel版本,因为使用了react-redux,所以它是所有实现方式中代码最精简的一个例子。
我们只看不同的部分,在src/index.js中,代码几乎和react_with_context一模一样,唯一的区别就是我们不再使用自己实现的Provider,而是从react-redux库导入Provider,代码如下:
1 | import {Provider} from 'react-redux'; |
有了react-redux,视图文件src/views/Counter.js和src/Summary.js中的代码可以变得相当简洁。
在前面的redux_smart_dumb和redux_with_context例子中,我们实际上分别实现了react-redux的两个最主要的功能:
connect:连接容器组件和傻瓜组件
Provider:提供包含store的context
现在我们直接使用react-redux提供的这两个功能了,让我们分别来详细介绍。
- 1) connect
以Counter组件为例,和redux_with_context中的代码不同,react-redux的例子中没有定义CounterContainer这样命名的容器组件,而是直接导出了这样一个语句。
1 | export default connect(mapStateToProps, mapDispatchToProps)(Counter); |
第一眼看去,会让人觉得这不是正常的JavaScript语法。其实,connect是react-redux提供的一个方法,这个方法接收两个参数mapStateToProps和mapDispatchToProps,执行结果依然是一个函数,所以才可以在后面又加一个圆括号,把connect函数执行的结果立刻执行,这一次参数是Counter这个傻瓜组件。
这里有两次函数执行,第一次是connect函数的执行,第二次是把connect函数返回的函数再次执行,最后产生的就是容器组件,功能相当于redux_smart_dumb中的CounterContainer。
当然,我们也可以把connect的结果赋值给一个变量CounterContainer,然后再export这个CounterContainer,只是connect已经大大简化了代码,习惯上可以直接导出函数执行结果,也不用纠结如何命名这个变量。
这个connect函数具体做了什么工作呢?
作为容器组件,要做的工作无外乎两件事:
把Store上的状态转化为内层傻瓜组件的props
把内层傻瓜组件中的用户动作转化为派送给store的动作
这两个工作一个是内层傻瓜对象的输入,一个是内层傻瓜对象的输出。
这两个工作的套路也很明显,把Store上的状态转化为内层组件的props,其实就是一个映射关系,去掉框架,最后就是一个mapStateToProps函数该做的事情。这个函数命名是业界习惯,因为它只是一个模块内的函数,所以实际上叫什么函数都行,如果觉得mapStateToProps这个函数名太长,也可以叫mapState,也是业界惯常的做法。
Counter组件对应的mapStateToProps函数代码如下:
1 | function mapStateToProps(state, ownProps) { |
把内层傻瓜组件中用户动作转化为派送给Store的动作,也就是把内层傻瓜组件暴露出来的函数类型的prop关联上dispatch函数的调用,每个prop代表的回调函数的主要区别就是dispatch函数的参数不同,这就是mapDispatchToProps函数做的事情,和mapStateToProps一样,这么长的函数名只是习惯问题,mapDispatchToProps也可以叫作mapDispatch。
Counter组件对应的mapDispathToProps函数代码如下:
1 | function mapDispatchToProps(dispatch, ownProps) { |
mapStateToProps和mapDispatchToProps都可以包含第二个参数,代表ownProps,也就是直接传递给外层容器组件的props,在ControlPanel的例子中没有用到,我们在后续章节中会有详细介绍。
- 2) Provider
我们在redux_with_context中已经完整实现了一个Provider,react-redux和我们例子中的Provider几乎一样,但是更加严谨,比如我们只要求store属性是一个object,而react-redux要求store不光是一个object,而且是必须包含三个函数的object,这三个函数分别是:
subscribe
dispatch
getState
拥有上述三个函数的对象,才能称之为一个Redux的store。
另外,react-redux定义了Provider的componentWillReceiveProps函数,在React组件的生命周期中,componentWillReceiveProps函数在每次重新渲染时都会调用到,react-redux在componentWillReceiveProps函数中会检查这一次渲染时代表store的prop和上一次的是否一样。如果不一样,就会给出警告,这样做是为了避免多次渲染用了不同的Redux Store。每个Redux应用只能有一个Redux Store,在整个Redux的生命周期中都应该保持Store的唯一性。
三、本章小结
在这一章中,我们首先从Redux的鼻祖Flux框架出发,通过创造一个ControlPanel的例子,了解了Flux“单向数据流”的原则。如果只由React来管理数据流,就很难管理拥有很多组件的大型应用,传统的MVC框架也有其缺陷,很容易写乱套,所以Flux是应用架构的一个巨大改进,但是Flux也有其缺点。
Redux是Flux框架的一个巨大改进,Redux强调单一数据源、保持状态只读和数据改变只能通过纯函数完成的基本原则,和React的UI=render(state)思想完全契合。我们在这一章中用不同方法,循序渐进的改进了ControlPanel这个应用的例子,为的就是更清晰地理解每个改进背后的动因,最后,我们终于通过react-redux完成了React和Redux的融合。
但是,这只是一个开始。接下来,我们将看到更加深入的React和Redux实践知识。